Last updated: February 24th, 2014
Based on scala/scala as of February 24th, 2014
TOC
- Goodies
- What's new in the new optimizer
- Test driving the new optimizer
- Getting Started
- Putting the new optimizer through its paces
- FAQ
- Comments, benchmarks, test cases, bug reports, are welcome
1 Goodies
Branch GenRefactored99sZ at repo https://github.com/magarciaEPFL/scala.git improves three areas of scalac: optimizer, code emitter, and AST-level representation of closures. The resulting compiler is on average 15% faster, and also emits more compact code than the mainline Scala compiler.
A small subset of the above functionality has already been merged and will be available in Scala 2.11 once it's released. However, the bulk of the new backend won't. For all practical purposes, don't use that small "subset" available in scalac. You'll be missing on the delta with respect to full-blown new backend, and it's a huge delta:
To get up and running, please skip to Getting Started.
1.1 Why a new optimizer
It might be the officially supported optimizer, but not everyone likes it. It's very telling a major Scala framework recommends against using it.
You might also have heard "everything will be better with MethodHandles". Well, who knows, it might turn out that way in the end. Instead, the new optimizer ("BCodeOpt") improves performance today, while leaving the door open to future developments (by handling lambdas in a manner that's forward-compatible with MethodHandles).
Additionally, the new optimizer is more maintainable: it consists of several focused, individually simple, transformations; that are combined to implement bytecode-level refactorings, using ASM http://asm.ow2.org/
1.2 And a faster code emitter, too
Before the new optimizer runs (BCodeOpt) the new bytecode emitter (GenBCode) turns Abstract Syntax Trees directly into ASM Trees, outperforming by 30% its existing counterpart (GenICode + GenASM).
- the intermediate step to build Control Flow Graphs is not needed,
- disk writing and class file building overlap (the more source files, the larger the speedup)
1.3 Leaner Closure ASTs
The release version of scalac processes closures by creating inner classes early in the compilation pipeline (the "traditional" approach to closure conversion). Instead, the new backend postpones the creation of AST nodes for closures, simplifying the job of specialization, erasure, and other compiler phases.
Under "modern" closure conversion, the bytecode emitter takes responsibility for producing the JVM-level representation of closures. This is the default (compiler option -Yclosurify:delegating ).
2 What's new in the new optimizer
2.1 Distinction between intra-program and cross-library optimizations
The existing inliner, once activated, will inline both callees found in external libraries (against which the program is being compiled) as well as callees in the program being compiled. There's no way to tell it to focus only in the intra-program case. The advantage of applying intra-program optimizations only is that at runtime updated libraries may be used (granted, binary compatible ones).
- intra-program optimizations are activated via
-Ybackend:o2 - cross-libraries optimizations are activated via
-Ybackend:o3
Details in Sec. 4.1.
2.2 Inlining
The inliner currently used in scalac has a few problems:
- closure elimination is implemented as repeated method inlinings. Upon being forced to stop with that (e.g., recursive method) none of the previous inlinings is undone, leaving both the closure class and a trail of duplicate code.
- code may be inlined from third-party libraries or the JDK. In general methods not marked
@inlinemay be inlined as discussed in thread the perils of inlining - invocation cycles (ie M1() calling M2() calling M1() etc) are "broken" only after hitting the maximum method size threshold, leaving a trail of duplicate code behind.
Instead, the new optimizer just follows a simple principle:
only inline @inline-marked methods, and always inline them, including under separate-compilation
Thus the new inliner is deterministic, not dependent on heuristics about method sizes or similar. The only additional requirement (if you will) is that the method to dispatch (the one marked @inline) can be found via the static type of the receiver, e.g. in a Range.foreach() callsite the type of the receiver must be Range or subtype (in general, not a super type where the @inline method is defined). After all, inlining is a conscious decision: making that explicit via the type of the receiver is straightforward. As a result, the @noinline annotation doesn't play a role anymore.
The new optimizer provides detailed logging about performed inlinings, as well as diagnostics when inlining proves unfeasible (down to the culprit bytecode instructions). With that, fixing the causes of non-inlining takes way less effort, as the following shows.
Log example:
[log jvm] Successful closure-inlining (albeit null receiver couldn't be ruled out). Callsite:
scala/tools/nsc/Global.exitingTyper(Lscala/Function0;)Ljava/lang/Object;
occurring in method
scala/tools/nsc/interpreter/JLineCompletion$CompilerCompletion$class::memberNamed(Lscala/tools/nsc/interpreter/JLineCompletion$CompilerCompletion;Ljava/lang/String;)Lscala/reflect/internal/Symbols$Symbol;
Warning example:
SpecializeTypes.scala:1166: warning: Closure-inlining failed because
scala/collection/immutable/List::mapConserve(Lscala/Function1;)Lscala/collection/immutable/List;
contains instruction
INVOKESPECIAL scala/collection/immutable/List.loop$1 (Lscala/collection/mutable/ListBuffer;Lscala/collection/immutable/List;Lscala/collection/immutable/List;Lscala/Function1;)Lscala/collection/immutable/List;
that would cause IllegalAccessError from class scala/tools/nsc/transform/SpecializeTypes
val parents1 = parents mapConserve specializedType
^
The warning makes sense: loop() is a local method:
// scala.collection.immutable.List
@inline final def mapConserve[B >: A <: AnyRef](f: A => B): List[B] = {
@tailrec
def loop(mapped: ListBuffer[B], unchanged: List[A], pending: List[A]): List[B] =
...
The bytecode-level counterpart, loop$1(), was emitted as private, as javap output shows:
private final
scala.collection.immutable.List
loop$1(scala.collection.mutable.ListBuffer,
scala.collection.immutable.List,
scala.collection.immutable.List,
scala.Function1);
...
2.3 GC-savvy closures: Singleton closures, Minimization of closure state
Some anonymous closures depend only on apply() arguments, for example the char filter function:
def deeplyNestedMethod(str: String) = {
str filter {
(char: Char) =>
(char >= 'a' && char <= 'f') ||
(char >= 'A' && char <= 'F') ||
(char >= '0' && char <= '9') }
}
In these cases, the new optimizer avoids repeated allocations by keeping (in a static field) a singleton-instance that is reused.
After dead-code elimination, closure state comprises only what is actually accessed.
These features are more useful on Android (besides micro-benchmarks) where a vast RAM doesn't masquerade redundant allocations.
2.4 Supported optimizations
2.4.1 Intra-method optimizations
- collapse a multi-jump chain to target its final destination via a single jump
- remove unreachable code
- remove those
LabelNodesandLineNumbersthat aren't in use - remove dangling exception handlers
- copy propagation
- dead-store elimination
- Preserve side-effects, but remove those (producer, consumer) pairs where the consumer is a
DROPand the producer has its value consumed only by theDROPin question. - simplify branches that need not be taken to get to their destination.
- nullness propagation
- constant folding
- caching repeatable reads of stable values
- eliding box/unbox pairs
- eliding redundant local vars
2.4.2 Intra-class optimizations
- those private members of a class which see no use are elided
- tree-shake unused closures, minimize the fields of those remaining
- minimization of closure-allocations
- refresh the InnerClasses JVM attribute
2.4.3 Whole-program optimizations
- method inlining
- closure inlining
3 Test driving the new optimizer
3.1 How much does it add to compilation time?
The new optimizer (except the whole-program step) is task-parallel:
- intra-method optimizations are run in parallel for different methods;
- intra-class optimizations are run in parallel for different classes
Visually:
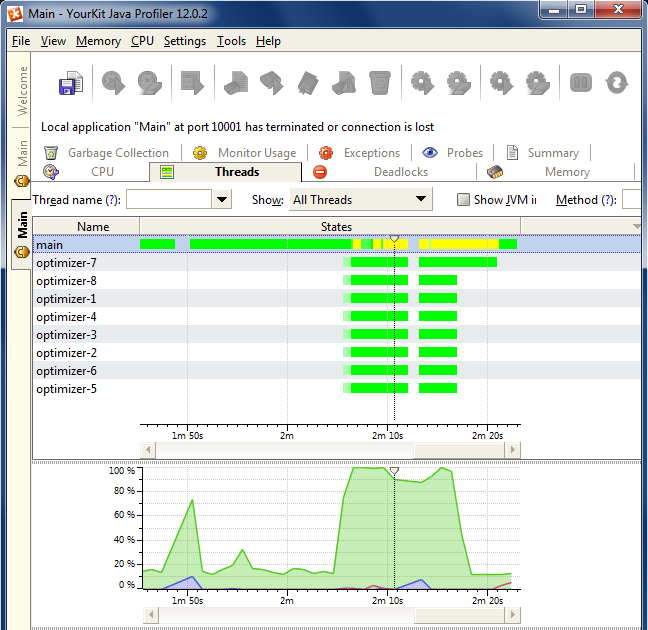
There's no reason to limit the worker pool to 8 threads, that's configurable via -Ybcode-emitter-threads N
3.2 Emitted code size
Let's take scala/scala as case study, compiling src/compiler and src/reflect (on the one hand) and the standard library (on the other) using:
- GenICode and GenASM.
- GenBCode (highlighted).
The new optimizer produces smaller JARs:
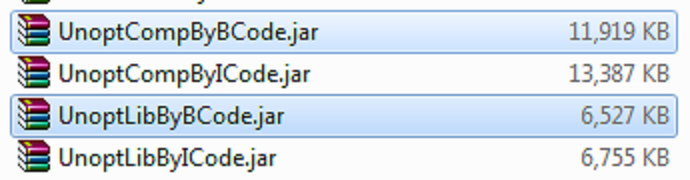
The above reflects not so much code reductions (in terms of instruction count) but smaller constant pools due to Late Closure Classes (an LCC just delegates to the class where the anon-closure is instantiated, which usually already has the constant pool entries that under "traditional" closure conversion have to be duplicated in the anon-closure-class).
To benefit from code size reductions as well, -Ybackend:o1 (intra-method optimizations) or up will do the trick. Moreover, on a multicore -Ybackend:o1 doesn't increase appreciably compilation time, I'm actually thinking making it default.
For example, method driver() in test/files/run/t7181.scala results in:
- 881 instructions, when compiled with
-Ybackend:o2 -Yclosurify:delegating - 1004 instructions, when compiled with
-Ybackend:GenASM -optimise(actually,-optimiseincreases code size, but the comparison with-Ybackend:o2is fair).
That's 881 vs 1004 instructions and not bytes, which still matters in case you're the one who has to read 881 vs 1004 lines of javap output.
3.3 Benchmarks
Feedback is welcome!
3.4 Speeding up scalac
Speedups in the range 10% to 20% have been observed against the latest scalac. The upper range is achieved by having a compiler optimized by the new optimizer compile using -Ybackend:GenBCode -Yclosurify:delegating (ie unoptimized compilation, using the new bytecode emitter and Leaner Closure ASTs). Just one data point:
[stopwatch] [locker.comp.timer: 1:43.359 sec]
...
[stopwatch] [quick.comp.timer: 1:32.335 sec]
Right now the new optimizer alone makes scalac only marginally faster. Instead, the 15% speedup mentioned above is due to the compiler doing less work: (a) Leaner Closure ASTs, (b) the new bytecode emitter, and (c) lower GC overhead. That's normal: scalac is dominated by factors not optimizable (at least not in the short term). Examples abound:
- millions of
::allocated. Neither the old nor the new optimizer are tuned to reduce that. - for deeper insights: https://github.com/gkossakowski/scalac-aspects
- actually, tools like Caliper or ScalaMeter, by themselves, tell how much faster something runs. When building an optimizer, it's more useful to know "why" something runs faster (specially with 20+ optimizations at play). With some work, the toolset that Grzegorz has jumpstarted can provide those insights.
The new optimizer may well make your code run faster. To find out, give it a try.
3.5 Bugs fixed
Previously, as bugs got fixed in the old optimizer, I proceeded to remove them from the list below. Later I realized doing so misrepresented (ie made appear smaller than it really is) the maintenance effort consumed by the old optimizer. Just imagine the list below but just longer.
- SI-3882 Regression with -optimise: "Illegal index: 0 overlaps List((variable par1,LONG))"
- SI-5286 avoid duplicating more than once a closure body when inlining a closure
- SI-5850 Inlined code shouldn't forget null-check on the original receiver
- SI-5950 Inlining creates duplicates when anon-closure-class can't be eliminated after all
-
SI-6105 Conditional optimization:
true || x == true, false && y == false - SI-6164 pipeline classfile building and writing (GenASM, GenBCode)
-
SI-6191 spurious
SCOPE_EXITwarnings - SI-6288 Wrong line number information in bytecode
- SI-6546 Optimizer leaves references to classes that have been eliminated by inlining
-
SI-6723 2.10 regression: inliner warnings with Map literal and
-optimize - SI-6759 Seek clarification about necessary and sufficient conditions for inclusion in InnerClasses JVM attribute
- SI-7050 phase closelim is a mess
- SI-7182 Finally blocks are duplicated for each 'return' in a try/catch/finally
- SI-7407 return inside try + pattern-match inside finally causes VerifyError
- SI-7518 inliner destroys line number information
- SI-7524 pathologically slow compilation time with -optimize and named/default arguments
- SI-7540 Optimizer changes behavior when pattern matching Some(X) scrutinee when X's type assumed wrong
- SI-7560 the ICode optimizer doesn't DCE-away trivial branches
-
SI-7589 VerifyError under
-Yinline -Yinline-handlers -
SI-7607 optimizer changes behavior of IDIV, LDIV, IREM, LREM bytecode instructions when the result is dropped
- SI-7792 Explicit return causes scalac -optimize to fail
- SI-7807 java.lang.VerifyError when using nested try/catch and ControlThrowable
- SI-8306 Contradiction: had an empty possible set indicating an uninitialized location
- SI-8315 crashy interplay between inlining, dead code elimination
- SI-8330 Mismatch in stack heights
- SI-8334 Crash in dead code elimination: could not find init
In addition:
- all
ICodeReaderbugs (the ASM class file reader is used instead) - all
-Ydelambdafy:methodbugs (the new backend doesn't require custom typing to represent lightweight-lambdas internally)
4 Getting Started
The first step is checking out branch GenRefactored99sZ of repository https://github.com/magarciaEPFL/scala
git clone git://github.com/magarciaEPFL/scala.git GenRefactored99sZ
cd GenRefactored99sZ
git checkout -b GenRefactored99sZ origin/GenRefactored99sZ
ant all.clean && ant
4.0 Using sbt to build your project with the new backend / optimizer
Section Using Scala from a local directory covers the changes needed in your project's Build.scala:
scalaVersion := "2.11.0-SNAPSHOT",
scalaHome := Some(file("scala-with-new-backend/build/pack")),
scalacOptions ++= Seq( . . . your options
"-Ybackend:o3", // the highest level of the new optimizer
. . . more of your options
),
where "scala-with-new-backend" is the folder one gets after following the steps in the sub-section above (cloning, checking out branch GenRefactored99sZ, building the compiler with ant).
4.1 Meaning of optimization levels
Each optimization level includes all optimizations from lower levels, and assume the new bytecode emitter (GenBCode) is active:
-Ybackend:GenASM | backdoor to use the old backend. |
-Ybackend:GenBCode | use the new code emitter, just emitting trees as delivered by CleanUp |
-Ybackend:o1 | Intra-method optimizations and all closure optimizations except closure stack-allocation (in detail: -Ybackend:o1 performs minimization of closure state and closure "singletonization") |
-Ybackend:o2 | Intra-program optimizations. This includes any method inlining and closure stack-allocation as long as it affects only what's being compiled, as opposed to peeking inside external libraries (see below). |
-Ybackend:o3 | Cross-libraries optimization: this includes the same kinds of optimization as above, with the caveat that bytecode from external can be parsed if needed to apply some optimization (e.g., this is the optimization level to picks to have Range.foreach inlined) |
Nota bene: In order to ease migration from old to new optimizer, for now no error is emitted when mixing compiler flags for old and new optimizer. In this case the compiler silently falls back to the old optimizer. This "feature" allows keeping the test suite as is: all those tests asking for -optimise or one of its variants can run without modification.
4.2 Choosing bytecode-level representation of closures
-Ydelambdafy:inline | Good ol' dedicated inner class for each closure. Available under GenASM (the only option there), and also with GenBCode but only up to -Ybackend:o1
|
-Yclosurify:delegating | aka "Late Closure Classes" ie their creation is postponed (instead of UnCurry during GenBCode) thus lowering the working set during compilation. Allows closure-related optimizations (all optimization levels supported) |
4.3 Diagnostics
Diagnostics are displayed via -Ylog:jvm , for more details add -Yinline-warnings and if that's not enough adding -Ydebug will show both the individual bytecode instructions subject of the message as well as a listing of the enclosing method (all in ASM textual format, which is always available unlike javap).
Another useful flag is -Ygen-asmp <folder> which similar to -Ygen-javap will emit textual files but in ASM format.
What others are doing:
- Notes from the JS pit: closure optimization
- Runtime metaprogramming via java.lang.invoke.MethodHandle
- A comparison of the memory behaviour of Java and Scala programs
5 Putting the new optimizer through its paces
5.1 Optimizing the compiler and the standard library themselves
An attempt to ant nightly on a clean checkout of branch GenRefactored99sZ doesn't achieve the desired effect, because the old optimizer is used (-optimize activates the old optimizer). In fact, the compiler used for the first time to compile the new backend doesn't understand yet flags like -Ybackend:o1.
In order to run the test suite under the new optimizer, one may hardcode the optimization level of choice as shown below (run ant quick.clean && ant for the update to take effect).
--- a/src/compiler/scala/tools/nsc/settings/ScalaSettings.scala
+++ b/src/compiler/scala/tools/nsc/settings/ScalaSettings.scala
@@ -218,7 +218,7 @@ trait ScalaSettings extends AbsScalaSettings
*/
val Ybackend = ChoiceSetting ("-Ybackend", "choice of bytecode emitter", "Choice of bytecode emitter.",
List("GenASM", "GenBCode", "o1", "o2", "o3"),
- "o1")
+ "o3")
With the optimization level hardcoded as shown above, one may also delete all occurrences of "-optimise" in build.xml and build-ant-macros.xml. That way, ant all.clean && ant && ant nightly will both run the test suite and build a distribution optimized under BCodeOpt.
5.2 Experimental features
In principle, method handles can help with specialization, structural types, and lambdas. The prototype in branch GenMHv3 puts MHs to work to replace anon-closure-classes, with mixed results (the good: smaller jars; the bad: performance on JDK7). For perspective, the delta with respect to the non-MethodHandles backend is:
https://github.com/magarciaEPFL/scala/compare/magarciaEPFL:GenRefactored14...GenMHv3
Sources can be obtained via:
git clone git://github.com/magarciaEPFL/scala.git GenMHv3
cd GenMHv3
git checkout -b GenMHv3 origin/GenMHv3
ant all.clean && ant
This prototype requires -target:jvm-1.7. Right now scalac doesn't produce the newest class file format of JDK8. In the meantime, -target:jvm-1.7 can be used on that platform. A discussion about performance at: https://groups.google.com/d/msg/scala-internals/uBxprJixpwk/jG78X1k_92IJ
6 FAQ
-
What are those Java sources doing in package
scala.tools.asm.optimiz?
Those Java classes are a thin layer of functionality on top of the ASM library, which is written in Java. Package scala.tools.asm.optimiz contains intra-method optimizations which can be performed without knowledge about Scala-level types. The bulk of the optimizer, in constrast, is written in Scala.
- If MethodHandles are slow on JDK7, how come other programming languages are happily using them?
There's no contradiction. Other languages use MethodHandles for what Scala would accomplish via structural types, and in that setting MHs are faster than Java reflection. Instead, the prototype described in Sec. 5.2 leverages MHs in an area far more important to Scala (anonymous closures), and in that setting they don't outperform the Late Closure Classes that the new backend emits.
- What about tests?
As Sec. 5.1 shows, the test suite passes under all optimization levels, from -Ybackend:GenBCode to -Ybackend:o1 through -Ybackend:o3. It's always possible to include additional tests, for a correct optimizer: they will also pass! Thus if you are not convinced about the correctness argument, how about finding counter-examples? If you find one, please post it at scala-internals for discussion.
7 Comments, benchmarks, test cases, bug reports, are welcome.
Please help us help you. Regarding additional tests, an offer you can't resist:
In case you'd like to shoot up your Scala contributor ranking at https://github.com/scala/scala/contributors consider this: YOUR TESTS ARE WELCOME !!!
How to write bytecode-level tests? It all starts subclassing BytecodeTest. As an example, a unit test for constant folding:
https://github.com/magarciaEPFL/scala/commit/3281236219ad0a7894a0c1c743e8550e2ce20dbf
Miguel Garcia http://lampwww.epfl.ch/~magarcia